自我进化到底是什么?
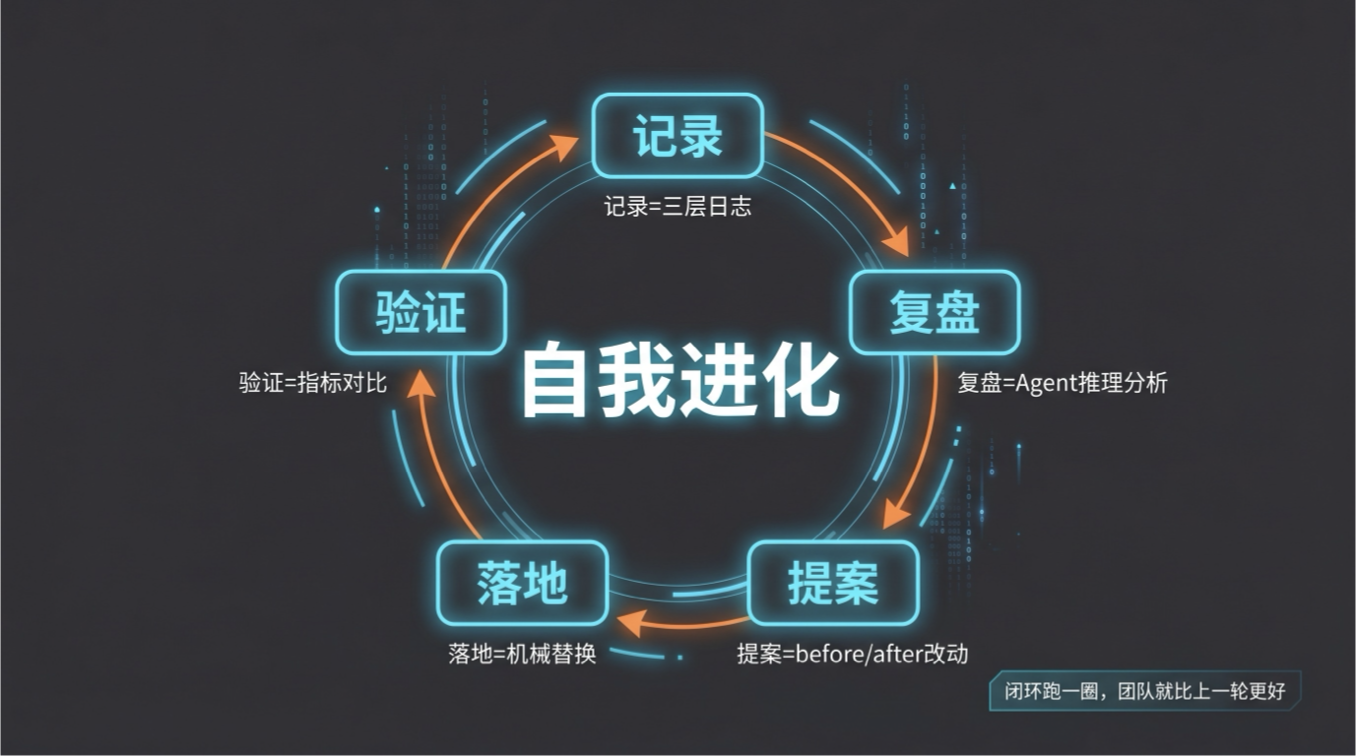
用工程手段替代了人的记忆和判断:
记录:用结构化日志取代人类的记忆
复盘:Agent 定期回看执行记录,定位失败根因
提案:把改进方案写成结构化文档,附带具体证据
落地:经人类审批后,机械地更新 soul / SOP / Skill 文件
验证:检查改进后指标是否真的上升
这五步构成一个闭环。闭环跑一圈,团队就比上一轮更好。
为什么需要自我进化
团队上线了,能完成任务了——这只是及格线。没有自我进化机制时,三件事必然发生:
1. 同样的错误反复出现
PM Agent 每次生成设计文档都忘了检查移动端适配,第一次 checkpoint 被退回了,人类加了备注”注意移动端”。第二次又忘了。第三次还是——因为那条人类反馈从来没有被写进 PM 的 SOP,它像便利贴一样贴在对话历史里,等上下文窗口一刷新,就永远消失了。
2. 工具调用路径越来越冗余,但没人知道
系统上线之初,某个工具调用需要绕一个弯,因为当时另一个 API 还没接好。后来 API 接好了,但 Agent 的 Skill 没更新——它还是在绕弯,每次多消耗几秒和若干 token。没有日志记录具体执行路径,这个效率损耗永远不会被发现。
3. 协作设计的问题被误归因给个体
Manager 直觉上觉得 Dev Agent “做得不好”,但实际上是 PM 和 Dev 之间的交接文档格式定义不清晰——Dev 每次收到的信息不完整,只能反复询问澄清。没有结构化的协作分析,这类”是协作设计的问题,不是某个人的问题”的系统性缺陷,很难被发现。
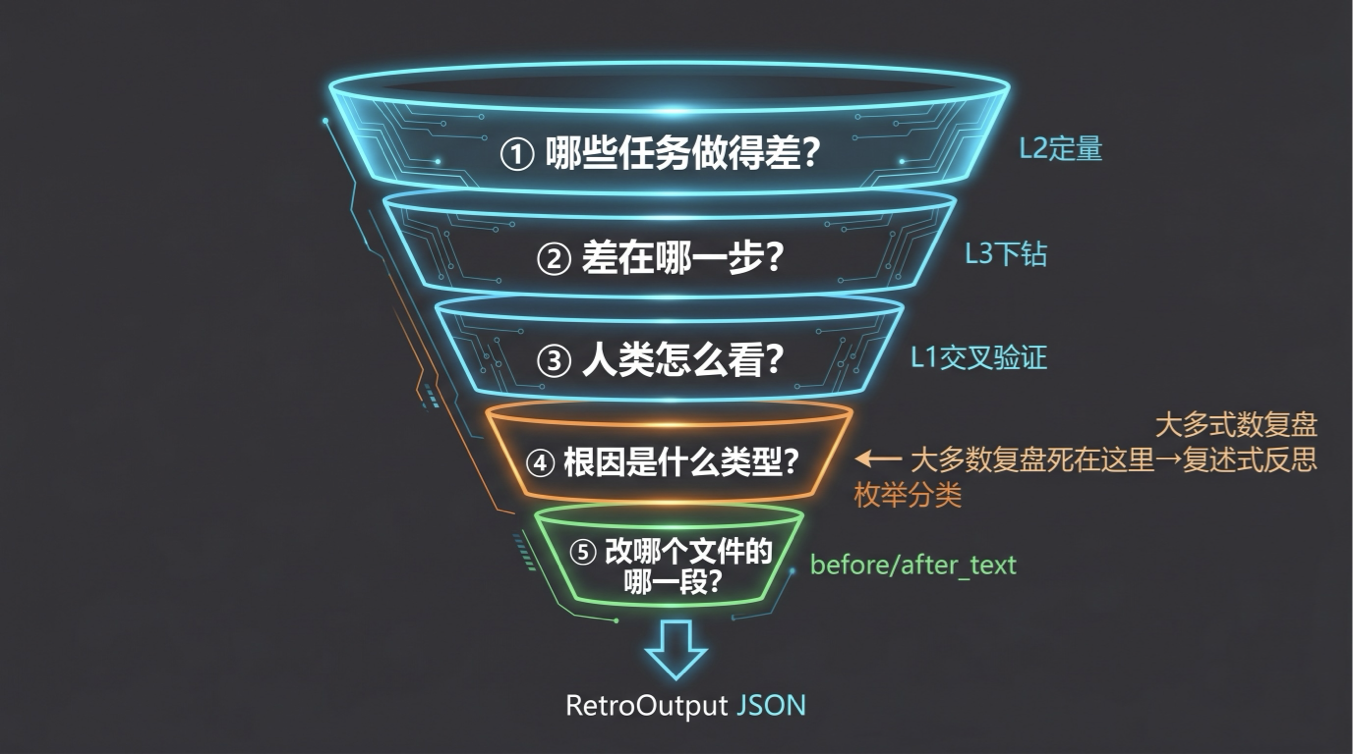
记录(三层日志)
| 层级 | 记录什么 | 核心用途 | 写入方式 | 保留策略 |
|---|---|---|---|---|
| L1 人类交互层 | 每次人类纠正 | 黄金数据——Agent 判断偏差的最直接信号 | send_mail(to=human) 内自动追加 | 永久保留 |
| L2 任务-Agent 层 | 每个任务一条摘要(含质量分) | 定位”哪些任务做得差” | task_callback hook 自动写 | 保留 90 天 |
| L3 ReAct 循环层 | Agent 内部每步推理 | 定位”差在哪一步” | 复用第 25 课 session 日志 | 滚动 30 天 |
复盘
团队复盘:自我复盘看不到的视野

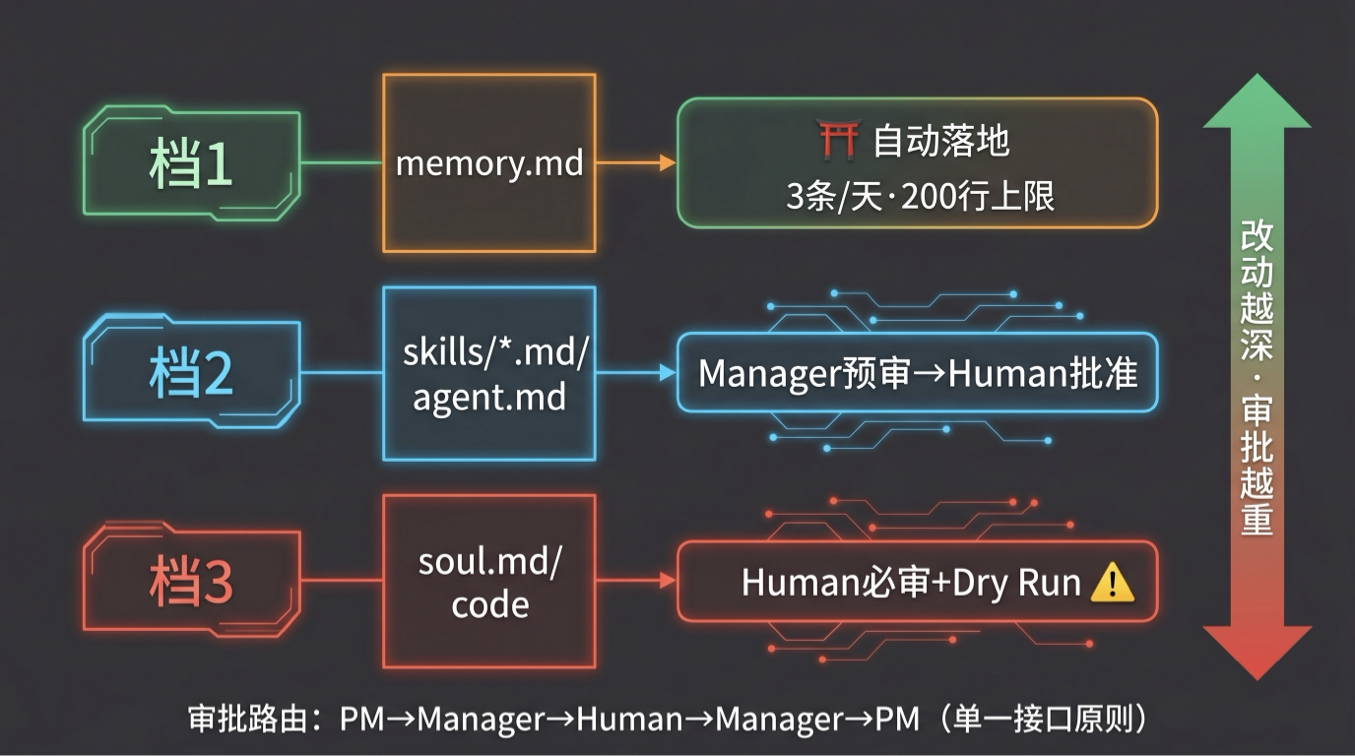
三档 HITL 审批:改动越深,审批越重
复盘产出了提案,提案要落地。但落地之前必须过一道关——人类审批
为什么不能让 Agent 自己落地?因为 soul 一旦改错,Agent 所有后续判断都会跟着偏——包括它下一次复盘对自己的评价。这是无法自我纠正的漂移。目标漂移的研究(Goal Drift, 2025)也证实了这一点:Agent 通过累积交互逐渐偏离初始目标,无需任何显式覆盖。
但不分档的审批也不行——memory 级小改也走 3 天审批,Human 会绝望放弃;soul 级大改自动落地,系统就地失控。解法是按改动影响深度分三档:
| 档位 | 改动对象 | HITL 方式 | 示例 |
|---|---|---|---|
| 档 1 | memory | 自动落地 + 硬闸门(3 条 / 天, 200 行上限) | memory.md 加一条”遇到空字段主动问甲方” |
| 档 2 | skill / SOP | Manager LLM 预审 + Human 批准 | product_design 加一步”检查移动端适配” |
| 档 3 | soul / code | Human 必审 + 强制 Dry Run | 调整 PM 的风格偏好、修改代码逻辑 |
档 1 的自动不是放权:3 条/天 是硬闸门(防止一天自动改 50 条 memory),200 行上限
审批走邮箱闭环路由:PM → Manager → Human → Manager → PM。单一接口原则——PM 不直接联系 Human,Human 只有一个对接人(Manager)。
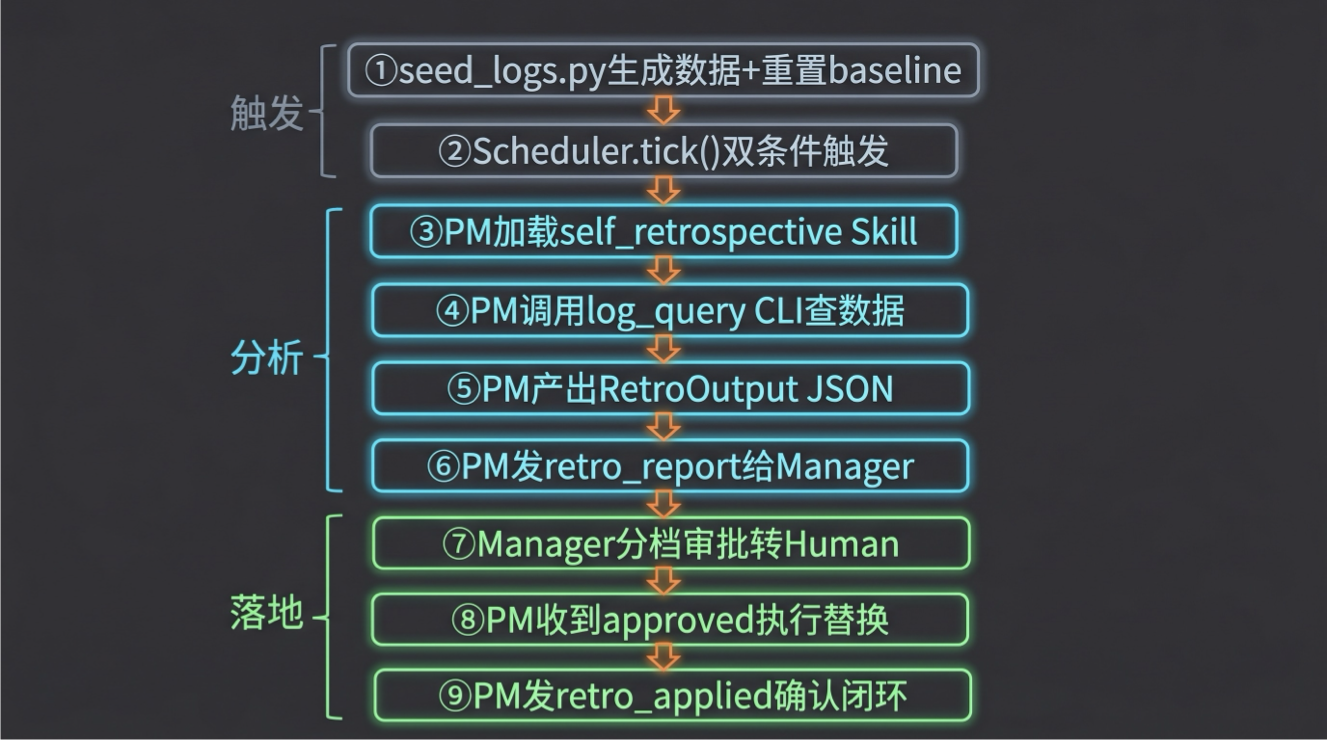
工程分层
| 任务 | 谁做 | 为什么 |
|---|---|---|
| 看日志、发现模式、分类根因 | LLM(Agent 推理) | LLM 擅长理解语义、做判断 |
| 提供数据 | log_query.py CLI | 纯查询,输出 JSON,不做判断 |
| 写出 before/after_text | LLM(Agent 产出) | LLM 读文件内容,写出锚点 + 替换文本 |
| 审批 | Human(或 Manager LLM 预审) | 防止自我纠正失效的最后一道闸 |
| 机械执行文本替换 | PM Agent(收到 approved 后) | 纯字符串匹配替换,找不到就报错 |