什么是MQ,干什么用的
消息队列,一种中间件,用于软件与软件之间通信的中间件产品MQ优点及缺点及常见问题
- 优点
异步处理 - 相比于传统的串行、并行方式,提高了系统吞吐量。
应用解耦 - 系统间通过消息通信,不用关心其他系统的处理。
流量削锋 - 可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请求。
日志处理 - 解决大量日志传输。
消息通讯 - 消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。 - 缺点
1、系统可用性降低
本来系统运行好好的,现在你非要加入个消息队列进去,那消息队列挂了,你的系统不是呵呵了。因此,系统可用性会降低;
2、系统复杂度提高
加入了消息队列,要多考虑很多方面的问题,比如:一致性问题、如何保证消息不被重复消费、如何保证消息可靠性传输等。因此,需要考虑的东西更多,复杂性增大。
3、一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。 - 常见问题
消息的顺序问题
消息有序指的是可以按照消息的发送顺序来消费
保证生产者-MQServer-消费者是一对一对一的关系即可,性能会有所下降
消息的重复问题
消费端处理消息的业务逻辑保持幂等性即可
- 解耦、异步、削峰是什么
- 解耦
A 系统发送数据到 BCD 三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果 C 系统现在不需要了呢?A 系统负责人几乎崩溃…A 系统跟其它各种乱七八糟的系统严重耦合,A 系统产生一条比较关键的数据,很多系统都需要 A 系统将这个数据发送过来。如果使用 MQ,A系统产生一条数据,发送到 MQ 里面去,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。这样下来,A 系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况 - 异步
A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 3ms,BCD 三个系统分别写库要 300ms、450ms、200ms。最终请求总延时是 3 + 300 + 450 + 200 = 953ms,接近 1s,用户感觉搞个什么东西,慢死了慢死了。用户通过浏览器发起请求。如果使用 MQ,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 3 + 5 = 8ms。 - 削峰
减少高峰时期对服务器压力。
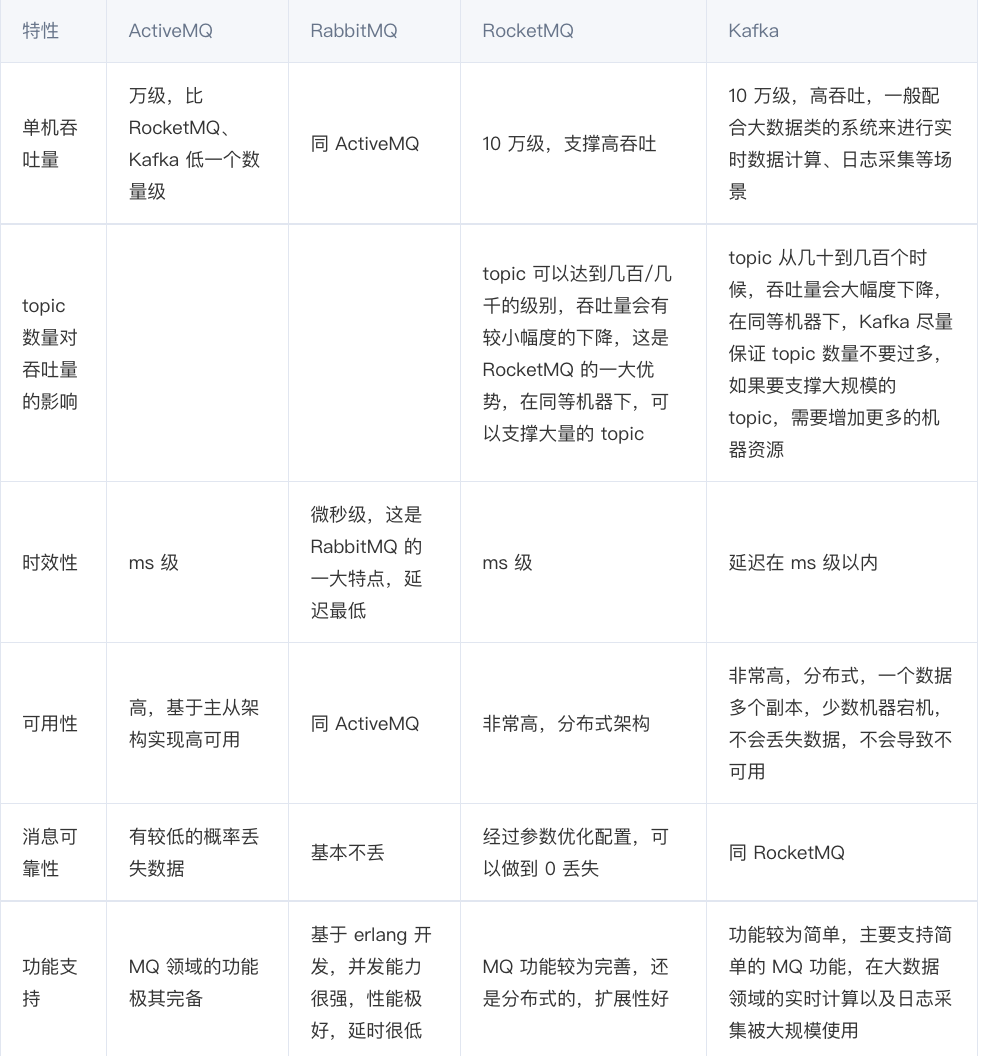
- 为什么选择 rabbitMQ
开源的,比较稳定的支持,活跃度也高
大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范
引入消息队列之后如何保证其高可用性
rabbitmq有三种模式:单机模式,普通集群模式,镜像集群模式延时队列如何实现
1、Redis的数据结构Zset,实现延迟队列的效果,主要利用它的score属性,redis通过score来为集合中的成员进行从小到大的排序
2、Redis 的key过期回调事件,也能达到延迟队列的效果,简单来说我们开启监听key是否过期的事件,一旦key过期会触发一个callback事件
3、RabbitMQ 自身并没有直接支持提供延迟队列功能,而是通过 RabbitMQ 消息队列的 TTL和 DXL这两个属性间接实现的
- 死信DL 死信交换机DLX
DLX即死信交换机,绑定在死信交换机上的即死信队列。RabbitMQ的 Queue(队列)可以配置两个参数x-dead-letter-exchange 和 x-dead-letter-routing-key(可选),一旦队列内出现了Dead Letter(死信),则按照这两个参数可以将消息重新路由到另一个Exchange(交换机),让消息重新被消费 - 死信产生的原因
消息或者队列的TTL过期
队列达到最大长度
消息被消费端拒绝(basic.reject or basic.nack)
- 如何避免消息重复投递和重复消费
在消息生产时,MQ内部针对每条生产者发送的消息生成一个inner-msg-id,作为去重的依据(消息投递失败并重传),避免重复的消息进入队列;
在消息消费时,要求消息体中必须要有一个 bizId(对于同一业务全局唯一,如支付ID、订单ID、帖子ID 等)作为去重的依据,避免同一条消息被重复消费
- 我的理解
每次消费信息过来时,唯一的 id 使用 redis 加锁,并设置过期时间,短时间内重复发送的直接过滤,当加锁过期时,根据业务场景写入 mysql 让其持久化,这样的话就确保了,不会被重复消费,所以重复投递都无所谓,随便投递,我只消费一次
信息基于什么传输
信道
由于TCP连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ使用信道的方式来传输数据。信道是建立在真实的TCP连接内的虚拟连接,且每条TCP连接上的信道数量没有限制几种路由模式
- 简单模式
一个生产者,一个消费者 - 工作队列模式
一个生产者,多个消费者,每个消费者获取到的消息唯一,默认轮询获取 - 发布/订阅模式(Fanout)
一个生产者发送的消息会被多个消费者获取。发送到Fanout Exchange的消息都会被转发到与该Exchange绑定(binding)的所有的Queue上。这种模式不需要任何Routekey,需要提前将Exchange 与Queue进行绑定,一个Exchange可以绑定多个Queue,一个Queue可以和多个Exchange绑定。如果接收到消息的Exchange没有与任何Queue绑定,则消息会丢失 - 路由模式(Direct)
任何发送到Direct Exchange的消息都会被转发到RouteKey指定的Queue,这种模式下不需要将Exchange进行任何绑定(binding)操作,消息传递时需要一个RouteKey,可以简单的理解为要发送到的队列名字。如果vhost中不存在该队列名,消息会丢失。 - 匹配订阅模式(Topic)
任何发送到Topic Exchange的消息都会被转发到所有关心RouteKey指定主题的Queue中。就是每个队列都有其关心的主题,所有的消息都带有一个标题(RouteKey),Exchange会将消息转发到所有关注主题能与RouteKey模糊匹配队列。这种模式需要Routekey并且提前绑定Exchange与Queue。在进行绑定时要提供一个该队列对应的主题。‘ # ’表示0个或若干个关键字,‘ * ’表示一个关键字。如果Exchange没有发现能够与RouteKey匹配的Queue,消息会丢失。 - headers
headers exchange主要通过发送的request message中的header进行匹配,其中匹配规则(x-match)又分为all和any,all代表必须所有的键值对匹配,any代表只要有一个键值对匹配即可。headers exchange的默认匹配规则(x-match)是any。
- 使用 rabbitMQ 有什么好处
参考问题2的优点 - 在那些场景下使用消息队列
1、服务间异步通信
2、顺序消费
3、定时任务
4、请求削峰 - 多个消费者监听一个队列时,消息如何分发
1、轮询
2、消息预取(预读)
3、公平分派(基于预读)
Exchange是什么?
Exchange类似于数据通信网络中的交换机,提供消息路由策略,producer不是通过信道直接将消息发送给queue,而是先发送给Exchange。一个Exchange可以和多个Queue进行绑定,producer在传递消息的时候,会传递一个ROUTING_KEY,Exchange会根据这个ROUTING_KEY按照特定的路由算法,将消息路由给指定的queue。和Queue一样,Exchange也可设置为持久化,临时或者自动删除。
Exchange的三种类型:
1、Direct:直接交换器,工作方式类似于单播,Exchange会将消息发送完全匹配ROUTING_KEY的Queue。
2、Fanout:广播交换器,不管消息的ROUTING_KEY设置为什么,Exchange都会将消息转发给所有绑定的Queue。
3、Topic:主题交换器,工作方式类似于组播,Exchange会将消息转发给和ROUTING_KEY模糊匹配的队列队列的工作流程
1、生产消息,发送给服务器端的Exchange
2、Exchange收到消息,根据ROUTINKEY,将消息转发给匹配的Queue
3、Queue收到消息,将消息发送给订阅者C
4、C收到消息,发送ACK给队列确认收到消息
5、Queue收到ACK,删除队列中缓存的此条消息本公司为什么使用rabbitMQ
怎么说呢,只要是个程序员都会这玩意,而且开源简单,最关键的是这不是我能决定的啊
- 场面话
支撑高并发、高吞吐、性能很高,同时有非常完善便捷的后台管理界面可以使用
还支持集群化、高可用部署架构、消息高可靠支持,功能较为完善
而且国内各大互联网公司落地大规模RabbitMQ集群支撑自身业务的case较多,国内各种中小型互联网公司使用RabbitMQ的实践也比较多,开源社区也比较活跃
rabbitMQ 由哪些组成
生产者, 消费者, broken(就是mq 自身serve), exchange, chanle(通道), queue , vhost(可以用来隔离环境的 ,什么测试版 和pre版本),还有就是消息 (message )bindkey 和 routingkey 的区别
binding key是队列和交换机之间的绑定key,而routing key是生产者发给交换机的一个信息,当routing key和binding key能对应上(类似于正则匹配)的时候就发到相应的队列中rabbitmq 如何确保消息被消费
noAck参数
RabbitMQ消费者消息确认(ACK)有两种机制,自动确认或者手动确认,自动确认就是消费者收到消息RabbitMQ就删除消息,手动确认,需要我们在代码层面主动调用Ack方法通知RabbitMQ,消息已经处理
ps:rabbitmq不会为未ack的消息设置超时时间,它判断此消息是否需要重新投递给消费者的唯一依据是消费该消息的消费者连接是否已经断开。这么设计的原因是rabbitmq允许消费者消费一条消息的时间可以很长。保证数据的最终一致性